Optimizing websites for ranking in search engines is an ever-precarious set of tasks. The algorithm Google uses to determine search results is a secret that evolves with each new release. Each time the algorithm is updated, Google gives out clues on what to look for. In a 2017 blog post, Google explained how crawl budget is not a factor in ranking. It shouldn’t be.
In simple terms, the crawl budget is the number of links Google will follow on your site. Your website’s crawl budget may be large or small depending on the size of your site, its popularity and its ease of use to crawl. Given that every site has a different amount of pages, it would be unfair to rank higher a site that gets crawled more simply because of its size.
Is Optimizing for Crawl Budget Worth It?
If the number of crawls on the site does not help rank, is crawl budget worth optimizing for? Yes, because it affects how many pages Googlebot (the name of the search engine crawler) reaches. Having Google spend the maximum time finding all of your site’s pages is the key to indexing. If the website has poor structure, carelessly shares links with other sites, reads like a technical manual and has no backlinks (popularity), the amount of crawl budget time is spent quickly and pages may get skipped.
Therefore, crawl budget does have an indirect effect on ranking.
What’s Your Site’s Crawl Budget?
Search Engine Optimization (SEO) specialists have a wealth of tools at their disposal for determining errors on a website that eat up crawl budget. The first step is to find out where your website stands. This can be done with the Sitemap and Google Webmaster Tools Search Console. Count the number of pages in your Sitemap and navigate to the Search Console page for Crawl Stats.
Example:
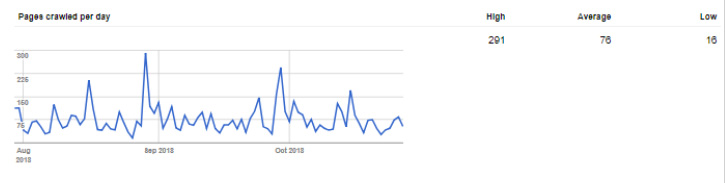
The theory is, if you take the number of pages in your Sitemap and divide by the average crawl number, you can determine how tight your crawl budget is. If the answer to your equation is 10, that means Google is crawling 10x fewer pages than average. That’s a serious problem.
You also need to look at “Pages crawled per day” and count this as links Google follows. If Googlebot finds and follows your link to Facebook, it considers that 1 crawl from your budget (and that bot has left your site).
Identifying Crawl Budget Issues
Logs. Logs. Logs. If you can get to your server logs, you can see which pages Googlebot visited and fix/optimize from there.
Tips for Getting the Most Out of Your Crawl Budget
The goal in optimizing for crawl budget is to have Google stay on your site and have all pages indexed. That way, all the work gone into keyword grooming and fixing headline tags can begin to payoff.
Here are a few strategies Foremost Media’s SEO team uses to keep search engine crawlers on your site as much as possible.
1. Sitemap / Robots.txt analysis
Your robots.txt file lives in the root of your site (www.example.com/robots.txt) and should specify where the Sitemap lives on your website. The Sitemap is used by Google as a guide for recent updates and new pages introduced to your site.
Issues to look out for:
- Remove any testing, demonstration or developer-only pages that snuck their way into the Sitemap. They take away crawl budget from your real pages that need indexing.
- Remove from the Sitemap any page that a user must be logged into ahead of time to access. If there is not a prompt to login, this will cause search crawlers to get a 404 error. Typically, 404 errors are not bad, but they do take away from the crawl budget. So, these pages are unnecessary in a Sitemap.
- Remove or fix urls in a Sitemap that become redirected to another page. Search bots want the actual page. Additionally, the redirect costs another crawl unit.
- Remove pages from the Sitemap that use the meta tag for NOINDEX. That’s another wasted crawl unit.
2. Run a Dead Link check of your site
As we know, a 404 doesn’t affect pagerank, but it does take away from the crawl budget. Dead links should be edited. Not only does it affect the amount of time that a search engine stays on your site, but it also creates a usability issue that needs to be addressed. Fixing this is easy. Go to www.deadlinkchecker.com and scan your website for free and fix from there.
3. Use FOLLOW / NOFOLLOW tags appropriately
When linking to internal pages on your site, the directive to search engines should be to follow those links. A penalty may occur if you add a NOFOLLOW directive on your internal links. It’s as though you don’t trust your own Web pages.
When linking to external pages, consider using the directive to tell search engines to NOFOLLOW the link. As each link is another unit off your “crawl budget”, sending the search bot off your site, may reduce crawls on your site. Declaring NOFOLLOW is appropriate for all of the URLs on a “Links page” (a list of Web links promoting sponsors or partners), links to the site’s social media and any other batches of external links (potentially in the site’s footer).
“Links pages” that are not relevant to the content of the page they are on could be viewed by Google as a link exchange. One search engine page ranking metric is to determine site popularity; this is done by counting inbound links to a website. When two sites exchange links without NOFOLLOW directives, both can be penalized as it’s interpreted as a spammy way to increase popularity without the substance of content. Google has become increasingly aware of this and rewards sites for appropriate uses of linking.
External links that have value to your content may be set to follow. Citation linking within content or linking to a blog author’s external profile site rewards the other site with a backlink from your site so you also may want to consider a nofollow tag on these types of links.
4. Get duplicate content under control!
Duplicate content is when two or more pages appear to be identical. In some content management systems (Wordpress for example), an article or blog post may be represented by several URLs. For example, /blog/title-of-page and /blog/post?id=13324 might have the same content. These need to be reigned in. One of the pages should 301 redirect to the other, or a canonical html tag should be implemented to tell the search engines that the target page is the authoritative content. Having two URLs with the same content will penalize your website ranking and use up more of that crawl budget allotment.
Learn From Our SEO Experts - Read More Below: